Dear fellow researchers, the paper that Salvo Finistrella, brilliant PhD student collaborating with me and Franco Zambonelli, published at ICAART 2026 is now available :)
Check it out here.

In that paper, Salvo put to test his own brand new simulator MininetGym, by comparing tabular and deep RL algorithms on two cybersecurity tasks.
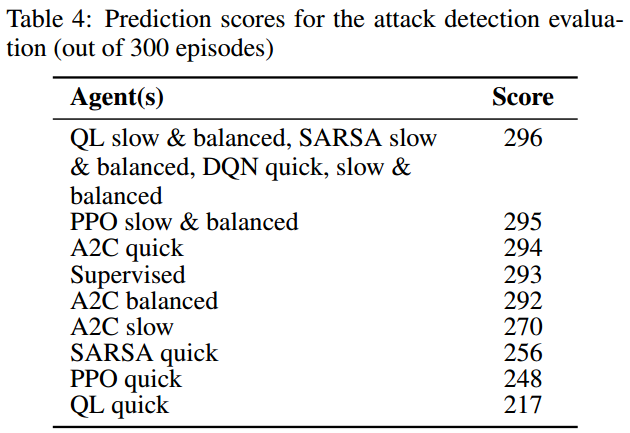
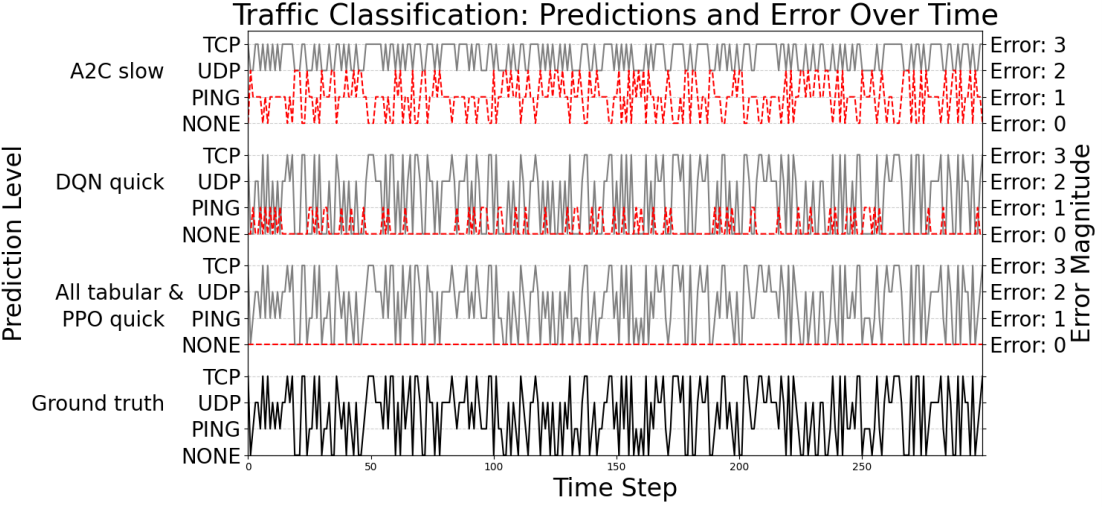
In particular, he also analysed the kind of errors that the learnt policies made, so as to provide a practically usable assessment of RL capabilities within the cybersecurity domain.
Finally, Salvo summarised the main takeaway lessons learned:
- ✅ Traffic classification and attack detection can be dealt with by RL
- 📉 Better training performance does not necessarily correlate to better generalisation
- ⚖️ Reward design should carefully balance false alarms with missed threats
Feel free to contact me for a pre-print, any inquiry, or even better to join us in this research :)
Peace.