I’m happy to announce that paper “Developing an ML pipeline for asthma and COPD: The case of a Dutch primary care service” has been published on Wiley International Journal of Intelligent Systems! Also this one took almost 2 years (:O), but here it is, finally :)
It is a joint work with Maarten M. H. Lahr, Esther Metting, Eloisa Vargiu, and Franco Zambonelli, all former members of the very successful and impactful EU H2020 project CONNECARE.
In brief, the paper describes a semi-automated ML pipeline delivering decision support to clinicians dealing with patients suffering from ashtma and/or COPD (Figure 1), starting with raw data readily available at primary care centres, and focussing on automation and trustwotrhiness to the real-world situation (e.g. minimal pre-processing). Data pre-processing, choice of predictive models, their training routines, and the scoring criteria are all described in due detail.
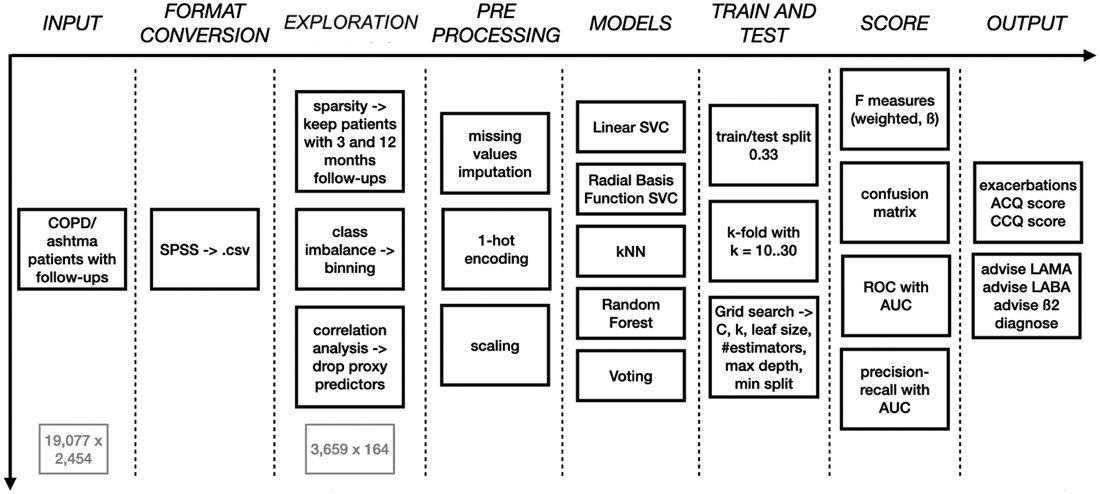
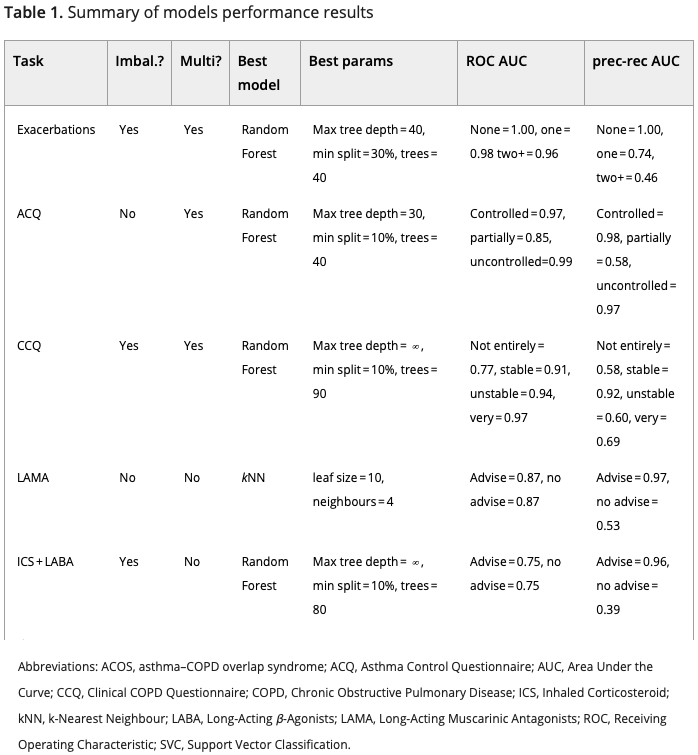
Then, performance results of the best trained models are discussed for each of the specific ML task accomplished:
- prediction of exacerbations
- prediction of ACQ category
- prediction of CCQ category
- advise of using LAMA
- advise of using ICS + LABA
- advise of using Beta2
- automated diagnosis (ashtma, COPD, ACOS)
A summary of these results is shown in Table 1 below.
Finally, we conclude with a synthesis of the lessons learnt during this real-world application of clinical decision support. In brief:
- Getting data takes time, so plan ahead
- Real-world data are a mess, so making data neat requires much more effort than training an ML model
- Exploratory analysis is crucial, so explore data with and without domain experts
- Involve domain experts (not only for evaluation), as domain experts add value at each stage of the pipeline
- Overfitting is tempting, but privilege automation over specialisation
- Automation is good, as automation adds value
- Handle scoring metrics with care, scoring has goals and assumptions: do not ignore them
Hope you enjoy reading, and contact me for any further inquiry :)